
UL IMCS participated in International Workshop on Semantic Evaluation (SemEval-2015) and specifically in Task 18 on Broad-Coverage Semantic Dependency Parsing (SDP 2015). Broad-coverage semantic dependency parsing is the task of recovering sentence-internal predicate–argument relationships for all content words, i.e. the semantic structure constituting the relational core of sentence meaning. SDP 2015 competition provided training data and evaluated SDP parsers for English, Czech, and Chinese languages.
The FrameNet based semantic parsing technology for Latvian developed within the National Research Programme is already exploited industrially through partnership projects with Latvian News Agency (LETA) and is described in several scientific papers ublished in international conferences. Meanwhile none of this provided an independent verification for the quality of our semantic parsing technology compared to the best parsing systems in the world. To clarify this and to rise the international recognition for UL IMCS achievements, we took part in the above-mentioned SemEval-2015, Task 18 international competition, where research teams from whole world compete to achieve the best parsing results for shared semantic parsing tasks.
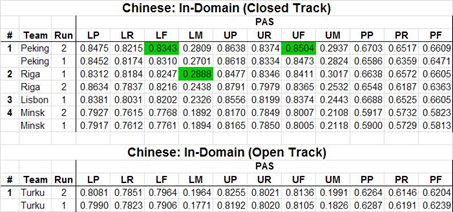
Results of Sem Eval 2015
We (Riga-team) are proud to finish this competition among the three best teams with results largely on par with Peking and Lisbon research teams. In this and last year SDP competitions took part more than 10 reasearch teams, including Cornegie Mellon University (CMU) from US, which was considered the leader in FrameNet semantic parsing. Results are available at http://svn.emmtee.net/sdp/public/2015/scores.ods . It is interesting to note that although we (Riga-team) were third on the official LF metric „F1-score for labeled graphs”, in other parameters we were first. For example, for the proportion of completely correctly parsed sentences in Chinese (LM metric: labeled exact match) we were first with slightly better result than Peking team.
A paper describing our system has been accepted for publication in NAACL’2015 conference



